
tg-me.com/knowledge_accumulator/39
Last Update:
AlphaTensor [2022] - пример сверхчеловеческой интуиции в математике
Подход "поиск + нейросетевая интуиция" позволил AlphaZero планировать в играх с помощью с обученной на огромном разнообразном датасете аппроксиматором функции полезности, позволившим радикально сократить пространство перебора.
Оказывается, существуют области, полезные в жизни, где мы понимаем, как применить такой подход на текущем этапе развития технологий. Такой областью является перемножение матриц!
Говоря общими словами (глубокий часовой обзор есть тут):
1) Наша задача - разработать алгоритм, который можно применить к 2 матрицам, чтобы получить в результате их произведение.
2) Мы работаем с пространством алгоритмов, которые задаются последовательностью векторов-параметров. Эти векторы-параметры говорят нам (хитро), что на что умножать и что с чем складывать.
3) В терминах RL действиями являются эти векторы, наградой является то, насколько близкий результат будет давать алгоритм (со штрафом за кол-во действий), а состоянием среды является размерность матриц и прошлые действия.
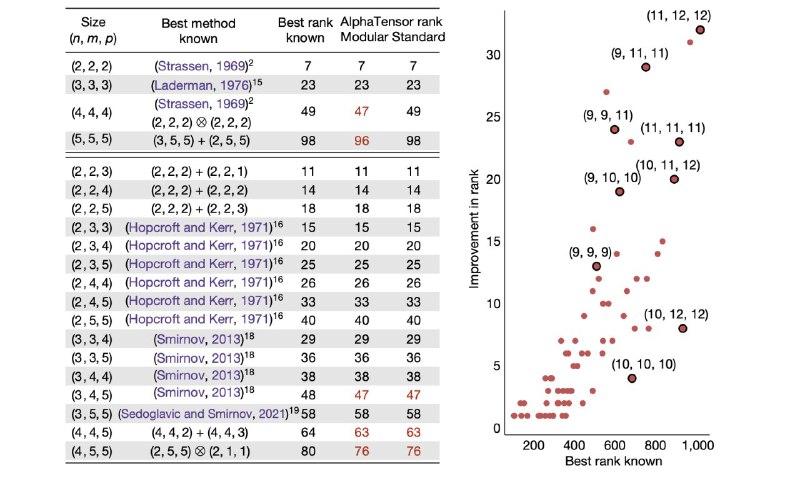
К этому всему мы применяем в точности AlphaZero - нужно только реализовать "RL-среду" по правилам выше. В результате обучения алгоритм находит более быстрые способы перемножать матрицы, чем знало человечество!
Я в восторге от результатов данной работы, потому что система демонстрирует сверхчеловеческое понимание своей задачи, а я люблю такое. Она способна смотреть на данные той размерности, которые мы не способны воспринимать. Результаты на картинке говорят, что чем больше размерность, тем больше отрыв между ней и нами. Такие вот дела!
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tg-me.com/knowledge_accumulator/39